Contents
Test out Aptible AI for your team

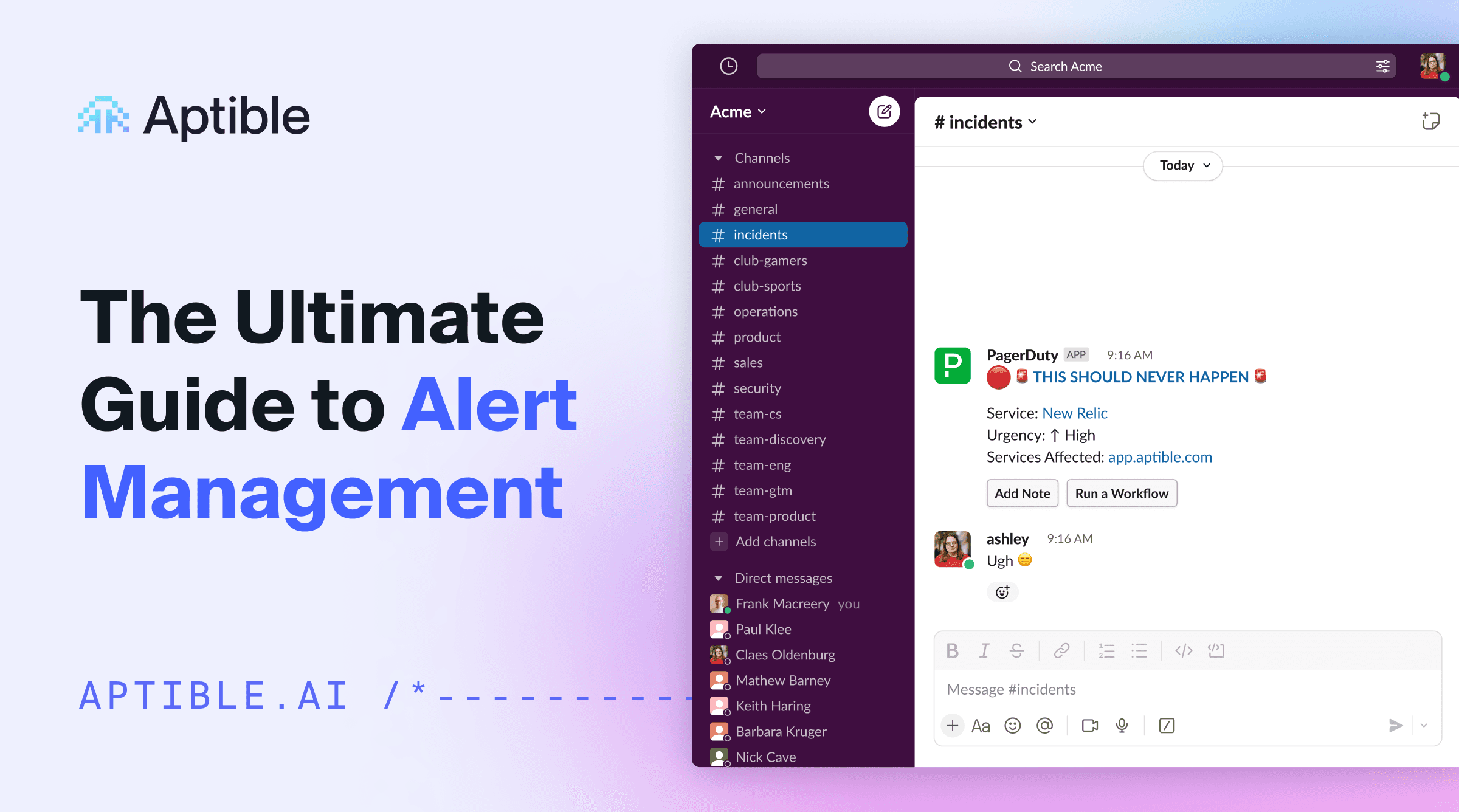
How to cut out alert noise, fight alert fatigue, and automate incident response
I’ve had the pleasure of being on-call more times over more years than I can count. So when given the chance to share some of my opinions about how engineering teams can handle alert management better, I jumped at the opportunity.
In the following guide, my goal is really only to help organizations implement a better alert management system that’s structured, actionable, and (when it makes sense) automated.
Fighting alert fatigue
I don’t think I’m being dramatic when I say that there is an alert fatigue epidemic plaguing on-call engineers right now.
Here’s what’s wrong:
On-call engineers get woken up for unclear, useless alerts with no documentation
Teams are either drowning in alert noise or they struggle with too few alerts and miss critical issues
Bad alert management is leading to burnout and turnover; engineers don’t want to spend their nights/mornings/weekends fixing issues that are seemingly impossible to diagnose or understand
On top of that, we’re seeing teams get smaller, consistently applying band-aid fixes to problems, creating useless alerts, and ultimately making their lives even harder for the following months and years.
Most teams don’t even have an alerting strategy. They have a mess of notifications, false positives, and messy monitoring tools. Let’s try to fix that, shall we?
So here’s what you can expect to learn in this guide:
How to cut alert noise by filtering out non-critical alerts
How to ensure every alert is actionable and comes with documentation
How to improve your team's on-call experience and prevent burnout
When to implement automation to reduce toil
Top 3 problems with alerting (and their hidden costs)
[01] Noisy alerts
Like I already mentioned, alert noise leads to alert fatigue leads to engineering burnout leads to high turnover leads to even worse alerts 🥲
I was on a discovery call recently where the prospect shared with us that his engineers are drowning in hundreds of alerts daily. They have a full-time employee whose only job is simply to process alerts.
Why does this happen?:
Engineers over-alert because it feels “safe”.
Infrastructure-based alerts trigger unnecessarily (i.e., you get a “server down” alert even when it doesn’t impact users).
Lack of alert management ownership — alerts get created but nobody maintains them.
The cost of over-alerting:
Engineers ignore alerts and miss critical incidents (take the Datadog outage, for example) 😬
Pager fatigue leads to slow response times 😴
On-call engineers suffer from alert anxiety 😥
[Potential] Solution: alert on user impact, not just infrastructure.
Stop alerting on “potential” failures as this often leads to false positives
Tie every alert to a dashboard (this requires more upfront work, but if you’ve got the bandwidth, I promise it’s worth it)
Use severity levels to prioritize. For example:
Warning (i.e., “Disk 80% full”)
Incident (i.e., “Customer databases failing”)
Hot take: Noisy alerting is worse than no alerting because it causes engineers to tune out the real problems, costing your business $$$.
[02] Unclear and useless alerts
This is an actual alert I got a few years ago: “🚨THIS SHOULD NEVER HAPPEN🚨”. First of all… what? If I’m going to get woken up by an alert at 2am, it better at least give me a hint as to what’s wrong.
And the person who created that alert had left the company ~8 years ago.
Why does this happen?:
Engineers leave but their alerts stay behind.
There are no runbooks or dashboards linked to the alerts.
Alerts are too vague (or sometimes too technical) without context.
The cost of useless alerts:
On-call engineers waste time reverse-engineering alerts ⏰
New hires have no idea what an alert means (and therefore have no idea what they’re doing)
As a result of the above, escalations increase.
[Potential] Solution: give context to every alert
When creating alerts, require documentation with clear steps to resolution.
Attach dashboards for quick diagnosis (this is what GitLab does, and it works very well for them — more on that later).
Audit alerts regularly to remove legacy alerts (I suggest quarterly, but that’s just me).
Hot take: If you wouldn’t wake up at 2am to handle it, then maybe it shouldn’t be an alert. Just something to consider 🤷♀️ **
[03] No defined ownership of alerts
As heard on another discovery call recently: “At [our company], developers create alerts but the ops team is responsible for responding. So they get paged for things they don’t understand.”
Why does this happen?:
Some teams let any engineer create alerts (resulting in a high volume of alerts as well as false positives)
Some teams have centralized company-wide alerting (but then engineers struggle to get the alerts they need added to the mix)
The cost of no clear ownership:
On-call engineers get paged for alerts they didn’t create (and also don’t understand) 😒
Fixing issues takes longer because responders lack critical context 🤔
Alert decay — no one knows which alerts are still relevant and which aren’t 😪
[Potential] Solution: Establish alert ownership (no duh, right?):
Use a hybrid model! Engineers can create their own alerts but they must must must document them and confirm that other team members who are responsible for response understand the documentation.
Assign clear ownership as part of your engineering culture. Hold owners accountable for hygiene and training.
Set up quarterly alert audits to review, update, or remove outdated alerts (I had to say this one twice because that’s how important it is to me 🥹)
Hot take: Every alert needs an owner; if nobody owns it, it’s just annoying noise and should be removed.
Accounting for organizational differences: how to choose the right alert management strategy
As will most things, the alert management strategy you choose will come with a number of tradeoffs:
Approach | Pros | Cons |
|---|---|---|
Every engineer can create alerts | Fast iteration | Leads to noise & undocumented alerts |
Centralized alerting | High-quality alerts | Engineers have no control, slow setup |
Hybrid approach (best practice IMO) | Balance of ownership & quality | Requires discipline to enforce |
Rather than preach at you, I’ll point you toward three companies that, in my humble opinion, are doing a decent job with their alert management strategies.
GitLab: alerts for on-call engineers at GitLab are based on user impact, NOT infrastructure failures. When an engineer creates an alert, they’re required to attach appropriate documentation and a single dashboard to help the on-call engineer determine exactly what the alert means and how to address it. Read more about their process here.
Canvas Health: engineers at Canvas Health (at least at some point in the not-so-distant past) were required to build a dashboard definition for the metrics they wanted to track after building a feature. While this process was mainly used for analytics, it also helped on-call engineers monitor those particular aspects of a feature.
Here’s an example to make it more tangible: if I’m an engineer that just created a new reporting interface and I want to know that users are able to generate their reports, I might create a dashboard that measures execution times of the queries or the response codes on the request as part of that feature development. Then I’d create and document alerts based off of that; if response times spike really high or there are a lot of errors, then the on-call engineer could refer to the dashboard to troubleshoot the problem.Aptible: at Aptible, we use a hybrid alert management model where engineers can set up alerts, but they must provide documentation. Unlike many companies, we actually lean toward more alerts than less — but our situation is a unique one because, as a PaaS, we’re doing incident management on behalf of hundreds of customers. Customer uptime is critical to the success of our business, and we can’t afford to miss critical alerts.
We also do regular audits to remove old or misleading alerts, and we commonly use PagerDuty reporting to track which alerts fire most often so that we can automate common fixes. More on that shortly!
How to cut out alert noise, fight alert fatigue, and automate incident response
I’ve had the pleasure of being on-call more times over more years than I can count. So when given the chance to share some of my opinions about how engineering teams can handle alert management better, I jumped at the opportunity.
In the following guide, my goal is really only to help organizations implement a better alert management system that’s structured, actionable, and (when it makes sense) automated.
Fighting alert fatigue
I don’t think I’m being dramatic when I say that there is an alert fatigue epidemic plaguing on-call engineers right now.
Here’s what’s wrong:
On-call engineers get woken up for unclear, useless alerts with no documentation
Teams are either drowning in alert noise or they struggle with too few alerts and miss critical issues
Bad alert management is leading to burnout and turnover; engineers don’t want to spend their nights/mornings/weekends fixing issues that are seemingly impossible to diagnose or understand
On top of that, we’re seeing teams get smaller, consistently applying band-aid fixes to problems, creating useless alerts, and ultimately making their lives even harder for the following months and years.
Most teams don’t even have an alerting strategy. They have a mess of notifications, false positives, and messy monitoring tools. Let’s try to fix that, shall we?
So here’s what you can expect to learn in this guide:
How to cut alert noise by filtering out non-critical alerts
How to ensure every alert is actionable and comes with documentation
How to improve your team's on-call experience and prevent burnout
When to implement automation to reduce toil
Top 3 problems with alerting (and their hidden costs)
[01] Noisy alerts
Like I already mentioned, alert noise leads to alert fatigue leads to engineering burnout leads to high turnover leads to even worse alerts 🥲
I was on a discovery call recently where the prospect shared with us that his engineers are drowning in hundreds of alerts daily. They have a full-time employee whose only job is simply to process alerts.
Why does this happen?:
Engineers over-alert because it feels “safe”.
Infrastructure-based alerts trigger unnecessarily (i.e., you get a “server down” alert even when it doesn’t impact users).
Lack of alert management ownership — alerts get created but nobody maintains them.
The cost of over-alerting:
Engineers ignore alerts and miss critical incidents (take the Datadog outage, for example) 😬
Pager fatigue leads to slow response times 😴
On-call engineers suffer from alert anxiety 😥
[Potential] Solution: alert on user impact, not just infrastructure.
Stop alerting on “potential” failures as this often leads to false positives
Tie every alert to a dashboard (this requires more upfront work, but if you’ve got the bandwidth, I promise it’s worth it)
Use severity levels to prioritize. For example:
Warning (i.e., “Disk 80% full”)
Incident (i.e., “Customer databases failing”)
Hot take: Noisy alerting is worse than no alerting because it causes engineers to tune out the real problems, costing your business $$$.
[02] Unclear and useless alerts
This is an actual alert I got a few years ago: “🚨THIS SHOULD NEVER HAPPEN🚨”. First of all… what? If I’m going to get woken up by an alert at 2am, it better at least give me a hint as to what’s wrong.
And the person who created that alert had left the company ~8 years ago.
Why does this happen?:
Engineers leave but their alerts stay behind.
There are no runbooks or dashboards linked to the alerts.
Alerts are too vague (or sometimes too technical) without context.
The cost of useless alerts:
On-call engineers waste time reverse-engineering alerts ⏰
New hires have no idea what an alert means (and therefore have no idea what they’re doing)
As a result of the above, escalations increase.
[Potential] Solution: give context to every alert
When creating alerts, require documentation with clear steps to resolution.
Attach dashboards for quick diagnosis (this is what GitLab does, and it works very well for them — more on that later).
Audit alerts regularly to remove legacy alerts (I suggest quarterly, but that’s just me).
Hot take: If you wouldn’t wake up at 2am to handle it, then maybe it shouldn’t be an alert. Just something to consider 🤷♀️ **
[03] No defined ownership of alerts
As heard on another discovery call recently: “At [our company], developers create alerts but the ops team is responsible for responding. So they get paged for things they don’t understand.”
Why does this happen?:
Some teams let any engineer create alerts (resulting in a high volume of alerts as well as false positives)
Some teams have centralized company-wide alerting (but then engineers struggle to get the alerts they need added to the mix)
The cost of no clear ownership:
On-call engineers get paged for alerts they didn’t create (and also don’t understand) 😒
Fixing issues takes longer because responders lack critical context 🤔
Alert decay — no one knows which alerts are still relevant and which aren’t 😪
[Potential] Solution: Establish alert ownership (no duh, right?):
Use a hybrid model! Engineers can create their own alerts but they must must must document them and confirm that other team members who are responsible for response understand the documentation.
Assign clear ownership as part of your engineering culture. Hold owners accountable for hygiene and training.
Set up quarterly alert audits to review, update, or remove outdated alerts (I had to say this one twice because that’s how important it is to me 🥹)
Hot take: Every alert needs an owner; if nobody owns it, it’s just annoying noise and should be removed.
Accounting for organizational differences: how to choose the right alert management strategy
As will most things, the alert management strategy you choose will come with a number of tradeoffs:
Approach | Pros | Cons |
|---|---|---|
Every engineer can create alerts | Fast iteration | Leads to noise & undocumented alerts |
Centralized alerting | High-quality alerts | Engineers have no control, slow setup |
Hybrid approach (best practice IMO) | Balance of ownership & quality | Requires discipline to enforce |
Rather than preach at you, I’ll point you toward three companies that, in my humble opinion, are doing a decent job with their alert management strategies.
GitLab: alerts for on-call engineers at GitLab are based on user impact, NOT infrastructure failures. When an engineer creates an alert, they’re required to attach appropriate documentation and a single dashboard to help the on-call engineer determine exactly what the alert means and how to address it. Read more about their process here.
Canvas Health: engineers at Canvas Health (at least at some point in the not-so-distant past) were required to build a dashboard definition for the metrics they wanted to track after building a feature. While this process was mainly used for analytics, it also helped on-call engineers monitor those particular aspects of a feature.
Here’s an example to make it more tangible: if I’m an engineer that just created a new reporting interface and I want to know that users are able to generate their reports, I might create a dashboard that measures execution times of the queries or the response codes on the request as part of that feature development. Then I’d create and document alerts based off of that; if response times spike really high or there are a lot of errors, then the on-call engineer could refer to the dashboard to troubleshoot the problem.Aptible: at Aptible, we use a hybrid alert management model where engineers can set up alerts, but they must provide documentation. Unlike many companies, we actually lean toward more alerts than less — but our situation is a unique one because, as a PaaS, we’re doing incident management on behalf of hundreds of customers. Customer uptime is critical to the success of our business, and we can’t afford to miss critical alerts.
We also do regular audits to remove old or misleading alerts, and we commonly use PagerDuty reporting to track which alerts fire most often so that we can automate common fixes. More on that shortly!
How to cut out alert noise, fight alert fatigue, and automate incident response
I’ve had the pleasure of being on-call more times over more years than I can count. So when given the chance to share some of my opinions about how engineering teams can handle alert management better, I jumped at the opportunity.
In the following guide, my goal is really only to help organizations implement a better alert management system that’s structured, actionable, and (when it makes sense) automated.
Fighting alert fatigue
I don’t think I’m being dramatic when I say that there is an alert fatigue epidemic plaguing on-call engineers right now.
Here’s what’s wrong:
On-call engineers get woken up for unclear, useless alerts with no documentation
Teams are either drowning in alert noise or they struggle with too few alerts and miss critical issues
Bad alert management is leading to burnout and turnover; engineers don’t want to spend their nights/mornings/weekends fixing issues that are seemingly impossible to diagnose or understand
On top of that, we’re seeing teams get smaller, consistently applying band-aid fixes to problems, creating useless alerts, and ultimately making their lives even harder for the following months and years.
Most teams don’t even have an alerting strategy. They have a mess of notifications, false positives, and messy monitoring tools. Let’s try to fix that, shall we?
So here’s what you can expect to learn in this guide:
How to cut alert noise by filtering out non-critical alerts
How to ensure every alert is actionable and comes with documentation
How to improve your team's on-call experience and prevent burnout
When to implement automation to reduce toil
Top 3 problems with alerting (and their hidden costs)
[01] Noisy alerts
Like I already mentioned, alert noise leads to alert fatigue leads to engineering burnout leads to high turnover leads to even worse alerts 🥲
I was on a discovery call recently where the prospect shared with us that his engineers are drowning in hundreds of alerts daily. They have a full-time employee whose only job is simply to process alerts.
Why does this happen?:
Engineers over-alert because it feels “safe”.
Infrastructure-based alerts trigger unnecessarily (i.e., you get a “server down” alert even when it doesn’t impact users).
Lack of alert management ownership — alerts get created but nobody maintains them.
The cost of over-alerting:
Engineers ignore alerts and miss critical incidents (take the Datadog outage, for example) 😬
Pager fatigue leads to slow response times 😴
On-call engineers suffer from alert anxiety 😥
[Potential] Solution: alert on user impact, not just infrastructure.
Stop alerting on “potential” failures as this often leads to false positives
Tie every alert to a dashboard (this requires more upfront work, but if you’ve got the bandwidth, I promise it’s worth it)
Use severity levels to prioritize. For example:
Warning (i.e., “Disk 80% full”)
Incident (i.e., “Customer databases failing”)
Hot take: Noisy alerting is worse than no alerting because it causes engineers to tune out the real problems, costing your business $$$.
[02] Unclear and useless alerts
This is an actual alert I got a few years ago: “🚨THIS SHOULD NEVER HAPPEN🚨”. First of all… what? If I’m going to get woken up by an alert at 2am, it better at least give me a hint as to what’s wrong.
And the person who created that alert had left the company ~8 years ago.
Why does this happen?:
Engineers leave but their alerts stay behind.
There are no runbooks or dashboards linked to the alerts.
Alerts are too vague (or sometimes too technical) without context.
The cost of useless alerts:
On-call engineers waste time reverse-engineering alerts ⏰
New hires have no idea what an alert means (and therefore have no idea what they’re doing)
As a result of the above, escalations increase.
[Potential] Solution: give context to every alert
When creating alerts, require documentation with clear steps to resolution.
Attach dashboards for quick diagnosis (this is what GitLab does, and it works very well for them — more on that later).
Audit alerts regularly to remove legacy alerts (I suggest quarterly, but that’s just me).
Hot take: If you wouldn’t wake up at 2am to handle it, then maybe it shouldn’t be an alert. Just something to consider 🤷♀️ **
[03] No defined ownership of alerts
As heard on another discovery call recently: “At [our company], developers create alerts but the ops team is responsible for responding. So they get paged for things they don’t understand.”
Why does this happen?:
Some teams let any engineer create alerts (resulting in a high volume of alerts as well as false positives)
Some teams have centralized company-wide alerting (but then engineers struggle to get the alerts they need added to the mix)
The cost of no clear ownership:
On-call engineers get paged for alerts they didn’t create (and also don’t understand) 😒
Fixing issues takes longer because responders lack critical context 🤔
Alert decay — no one knows which alerts are still relevant and which aren’t 😪
[Potential] Solution: Establish alert ownership (no duh, right?):
Use a hybrid model! Engineers can create their own alerts but they must must must document them and confirm that other team members who are responsible for response understand the documentation.
Assign clear ownership as part of your engineering culture. Hold owners accountable for hygiene and training.
Set up quarterly alert audits to review, update, or remove outdated alerts (I had to say this one twice because that’s how important it is to me 🥹)
Hot take: Every alert needs an owner; if nobody owns it, it’s just annoying noise and should be removed.
Accounting for organizational differences: how to choose the right alert management strategy
As will most things, the alert management strategy you choose will come with a number of tradeoffs:
Approach | Pros | Cons |
|---|---|---|
Every engineer can create alerts | Fast iteration | Leads to noise & undocumented alerts |
Centralized alerting | High-quality alerts | Engineers have no control, slow setup |
Hybrid approach (best practice IMO) | Balance of ownership & quality | Requires discipline to enforce |
Rather than preach at you, I’ll point you toward three companies that, in my humble opinion, are doing a decent job with their alert management strategies.
GitLab: alerts for on-call engineers at GitLab are based on user impact, NOT infrastructure failures. When an engineer creates an alert, they’re required to attach appropriate documentation and a single dashboard to help the on-call engineer determine exactly what the alert means and how to address it. Read more about their process here.
Canvas Health: engineers at Canvas Health (at least at some point in the not-so-distant past) were required to build a dashboard definition for the metrics they wanted to track after building a feature. While this process was mainly used for analytics, it also helped on-call engineers monitor those particular aspects of a feature.
Here’s an example to make it more tangible: if I’m an engineer that just created a new reporting interface and I want to know that users are able to generate their reports, I might create a dashboard that measures execution times of the queries or the response codes on the request as part of that feature development. Then I’d create and document alerts based off of that; if response times spike really high or there are a lot of errors, then the on-call engineer could refer to the dashboard to troubleshoot the problem.Aptible: at Aptible, we use a hybrid alert management model where engineers can set up alerts, but they must provide documentation. Unlike many companies, we actually lean toward more alerts than less — but our situation is a unique one because, as a PaaS, we’re doing incident management on behalf of hundreds of customers. Customer uptime is critical to the success of our business, and we can’t afford to miss critical alerts.
We also do regular audits to remove old or misleading alerts, and we commonly use PagerDuty reporting to track which alerts fire most often so that we can automate common fixes. More on that shortly!
Test out Aptible AI for your team
When is it time to automate your alerts?
In an ideal world, you’d be automating anything you’re getting paged for repeatedly. But alas, that is much easier said than done. As with determining how much alert noise is appropriate and who should own the setup of alerts, automating vs. not automating comes with its own tradeoffs.
Many of you are likely already familiar with Google’s SRE book; here’s an overview of the section on automation that I think is particularly helpful for understanding when to automate alerts:
Stage | What it means | Outcome |
|---|---|---|
No automation | Engineers manually recover all failing instances | Consistently time-consuming toil in comparison to automating |
Local script | Engineers run scripts on their machines | Not scalable |
Runbook automation | Predefined steps trigger an automated fix | Faster response time, though it requires more upfront effort |
Full automation | System self-recovers and notifies the customer | Zero engineering intervention, but potential for edge cases and missed outages |
Here’s the rub: it’s the smallest engineering teams that need the most automation to save themselves from burnout and turnover… But because automating alerts requires time and investment upfront, the smallest teams can’t afford to do it.
There’s no perfect answer to this problem, and I understand that this section is particularly grim, but FWIW, here’s my two cents: if an alert fires too often, automate the resolution instead of waking up engineers. You’ll thank yourself later.
On-call and turnover: How to prevent alert fatigue and engineering burnout
I’ve mentioned this several times, but the whole “alert fatigue epidemic” is incredibly painful because it’s a never-ending cycle: alerts cause burnout; burnout causes turnover; high turnover causes bad alerting.
As a victim of both the burnout and the stress of managing a burnt out team, I’m all too familiar with this particular problem. Here’s my advice:
Strive for no engineering turnover (I sort of say this in jest, of course, but… seriously — prioritize it).
Rotate on-call schedules fairly.
Prioritize knowledge transfer before employees leave.
Set up and stick to a stringent alert management and alerting hygiene routine (delete or update old alerts as regularly as you can).
Wrapping up
I know we covered a lot of ground, and a large part of this guide is more philosophical than practical, but that’s the whole thing about alert management: there’s no perfect way to do it.
At the end of the day, IT alerting shouldn’t be a nightmare; it should be a tool that helps engineers respond faster with less stress. If you skipped everything else and only read this, my advice is to start with small changes:
Audit and clean up your alerts now if you haven’t recently
Require documentation for all your alerts, regardless of who’s owning them
When possible, automate the alerts that you can — reducing noise even by a small fraction is worth it if it helps to retain your engineering team
Finally, if you want to dive even deeper on how other companies are handling alerting, here are a few alerting resources I’ve found particularly useful:
When is it time to automate your alerts?
In an ideal world, you’d be automating anything you’re getting paged for repeatedly. But alas, that is much easier said than done. As with determining how much alert noise is appropriate and who should own the setup of alerts, automating vs. not automating comes with its own tradeoffs.
Many of you are likely already familiar with Google’s SRE book; here’s an overview of the section on automation that I think is particularly helpful for understanding when to automate alerts:
Stage | What it means | Outcome |
|---|---|---|
No automation | Engineers manually recover all failing instances | Consistently time-consuming toil in comparison to automating |
Local script | Engineers run scripts on their machines | Not scalable |
Runbook automation | Predefined steps trigger an automated fix | Faster response time, though it requires more upfront effort |
Full automation | System self-recovers and notifies the customer | Zero engineering intervention, but potential for edge cases and missed outages |
Here’s the rub: it’s the smallest engineering teams that need the most automation to save themselves from burnout and turnover… But because automating alerts requires time and investment upfront, the smallest teams can’t afford to do it.
There’s no perfect answer to this problem, and I understand that this section is particularly grim, but FWIW, here’s my two cents: if an alert fires too often, automate the resolution instead of waking up engineers. You’ll thank yourself later.
On-call and turnover: How to prevent alert fatigue and engineering burnout
I’ve mentioned this several times, but the whole “alert fatigue epidemic” is incredibly painful because it’s a never-ending cycle: alerts cause burnout; burnout causes turnover; high turnover causes bad alerting.
As a victim of both the burnout and the stress of managing a burnt out team, I’m all too familiar with this particular problem. Here’s my advice:
Strive for no engineering turnover (I sort of say this in jest, of course, but… seriously — prioritize it).
Rotate on-call schedules fairly.
Prioritize knowledge transfer before employees leave.
Set up and stick to a stringent alert management and alerting hygiene routine (delete or update old alerts as regularly as you can).
Wrapping up
I know we covered a lot of ground, and a large part of this guide is more philosophical than practical, but that’s the whole thing about alert management: there’s no perfect way to do it.
At the end of the day, IT alerting shouldn’t be a nightmare; it should be a tool that helps engineers respond faster with less stress. If you skipped everything else and only read this, my advice is to start with small changes:
Audit and clean up your alerts now if you haven’t recently
Require documentation for all your alerts, regardless of who’s owning them
When possible, automate the alerts that you can — reducing noise even by a small fraction is worth it if it helps to retain your engineering team
Finally, if you want to dive even deeper on how other companies are handling alerting, here are a few alerting resources I’ve found particularly useful:
When is it time to automate your alerts?
In an ideal world, you’d be automating anything you’re getting paged for repeatedly. But alas, that is much easier said than done. As with determining how much alert noise is appropriate and who should own the setup of alerts, automating vs. not automating comes with its own tradeoffs.
Many of you are likely already familiar with Google’s SRE book; here’s an overview of the section on automation that I think is particularly helpful for understanding when to automate alerts:
Stage | What it means | Outcome |
|---|---|---|
No automation | Engineers manually recover all failing instances | Consistently time-consuming toil in comparison to automating |
Local script | Engineers run scripts on their machines | Not scalable |
Runbook automation | Predefined steps trigger an automated fix | Faster response time, though it requires more upfront effort |
Full automation | System self-recovers and notifies the customer | Zero engineering intervention, but potential for edge cases and missed outages |
Here’s the rub: it’s the smallest engineering teams that need the most automation to save themselves from burnout and turnover… But because automating alerts requires time and investment upfront, the smallest teams can’t afford to do it.
There’s no perfect answer to this problem, and I understand that this section is particularly grim, but FWIW, here’s my two cents: if an alert fires too often, automate the resolution instead of waking up engineers. You’ll thank yourself later.
On-call and turnover: How to prevent alert fatigue and engineering burnout
I’ve mentioned this several times, but the whole “alert fatigue epidemic” is incredibly painful because it’s a never-ending cycle: alerts cause burnout; burnout causes turnover; high turnover causes bad alerting.
As a victim of both the burnout and the stress of managing a burnt out team, I’m all too familiar with this particular problem. Here’s my advice:
Strive for no engineering turnover (I sort of say this in jest, of course, but… seriously — prioritize it).
Rotate on-call schedules fairly.
Prioritize knowledge transfer before employees leave.
Set up and stick to a stringent alert management and alerting hygiene routine (delete or update old alerts as regularly as you can).
Wrapping up
I know we covered a lot of ground, and a large part of this guide is more philosophical than practical, but that’s the whole thing about alert management: there’s no perfect way to do it.
At the end of the day, IT alerting shouldn’t be a nightmare; it should be a tool that helps engineers respond faster with less stress. If you skipped everything else and only read this, my advice is to start with small changes:
Audit and clean up your alerts now if you haven’t recently
Require documentation for all your alerts, regardless of who’s owning them
When possible, automate the alerts that you can — reducing noise even by a small fraction is worth it if it helps to retain your engineering team
Finally, if you want to dive even deeper on how other companies are handling alerting, here are a few alerting resources I’ve found particularly useful:
Questions?
Don't want to build your own? Try Aptible AI.

Don't want to build your own? Try Aptible AI.
Don't want to build your own? Try Aptible AI.